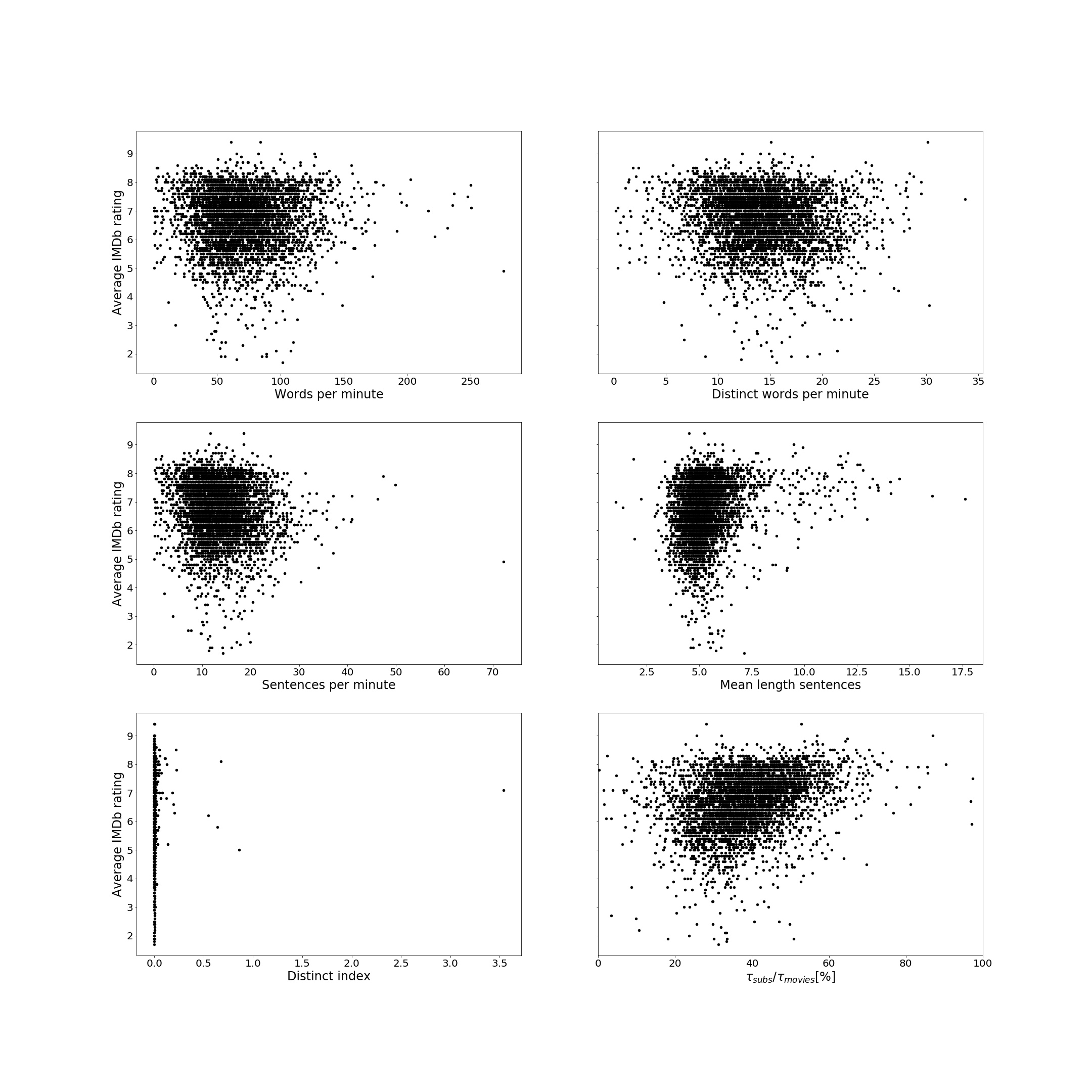
Exploration
Time
After the data cleaning we have 4,127 movie subtitles distributed across time in the following way.
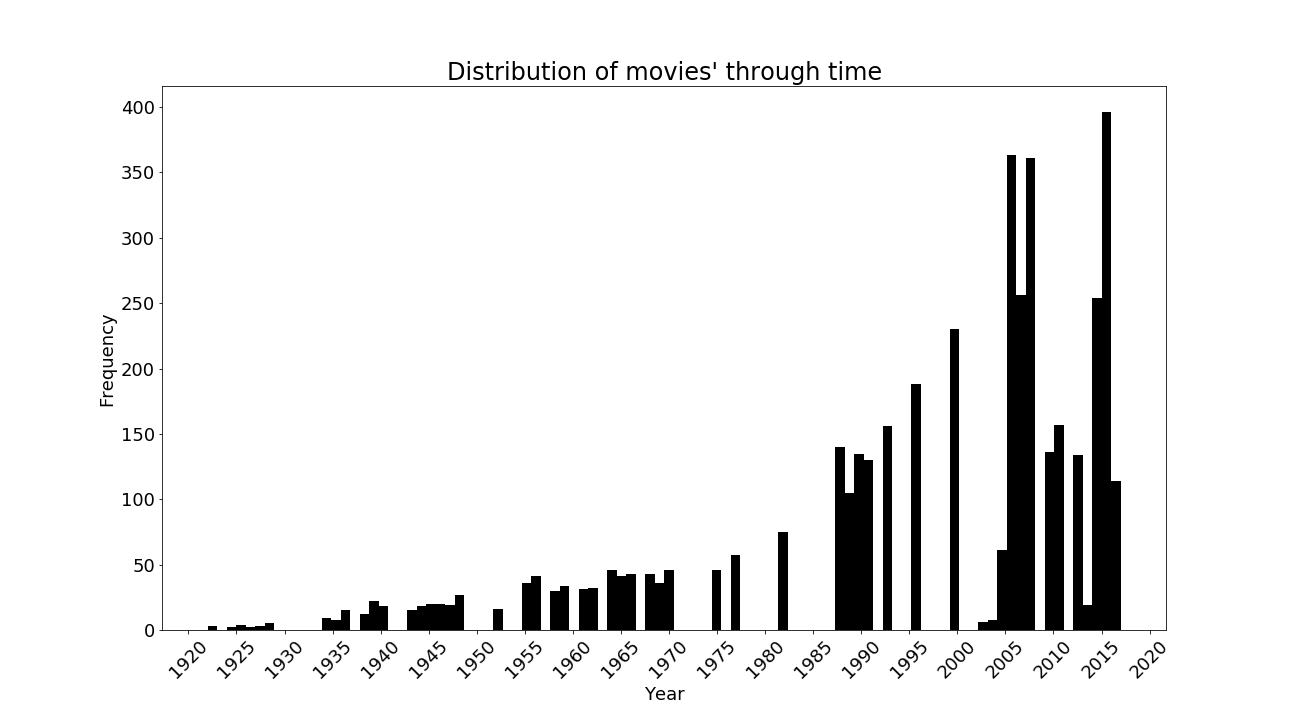
We see from our plot that our data is not evenly distributed. Most of our subtitles come from recent films, thus making an accurate time analysis complicated. Notice how incomplete our dataset is. Certain years have no movies as we see significant gaps in the 1970s and 1980s. The following table also confirms that more than half of our data points are in the 2000s and that we have very few movies before 1960.
| Period | Count | Average Rating |
|---|---|---|
| 1910-1959 | 379 | 7.58 |
| 1960-1999 | 1350 | 6.83 |
| 2000s | 2495 | 6.47 |
It also seems that recent movies tend to have a worse average rating, while the best films are the older ones. We attribute this to the idea that more data has been collected in recent years, regardless of whether movies are good or bad, while subtitles available for old movies are primarily for good movies. Due to the uneven distribution of movies across time, we believe it would be difficult to take time as a good feature to predict the rating. Intuitively, the release year of a movie has little to do with its rating.
Genres
Different movie genres typically have different characteristics and so we explore statistical features of genres. We explore the distribution of the different genres in our dataset.
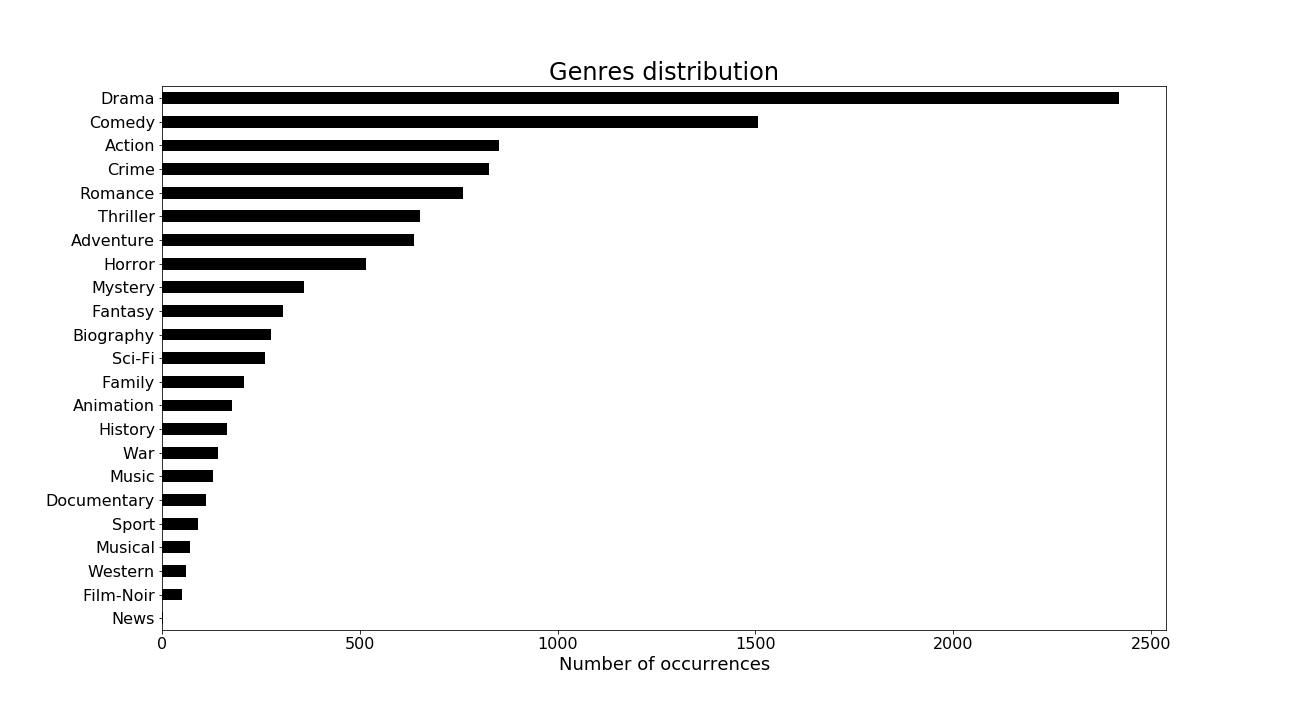
Drama is the most frequent genre in our dataset. Since we saw that our dataset had years with no subtitles data and was thus fairly incomplete, we compare the average IMDb rating of our movie's subtitles dataset for the 10 most frequent genres to the corresponding genre average rating on the whole IMDb database.
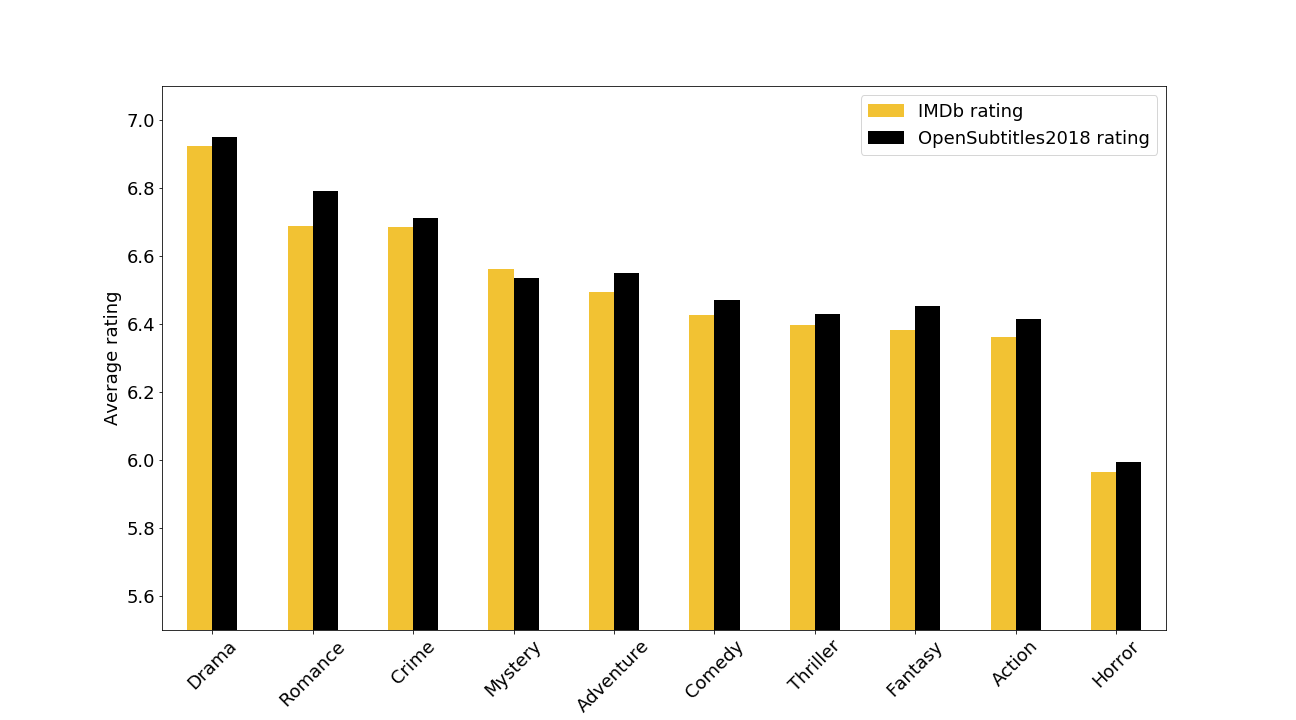
We see that for each genre there isn't much difference between the average IMDb rating and the OpenSubtitles2018 rating. Despite the incompleteness of our dataset across time, each genre's average IMDb rating in our dataset is fairly representative of the genre's IMDb rating. We also notice the wide gap between Drama movies' and Horror movies' average rating. We can therefore hypothesize that a movie's genre has an influence on its average rating.
Average Rating
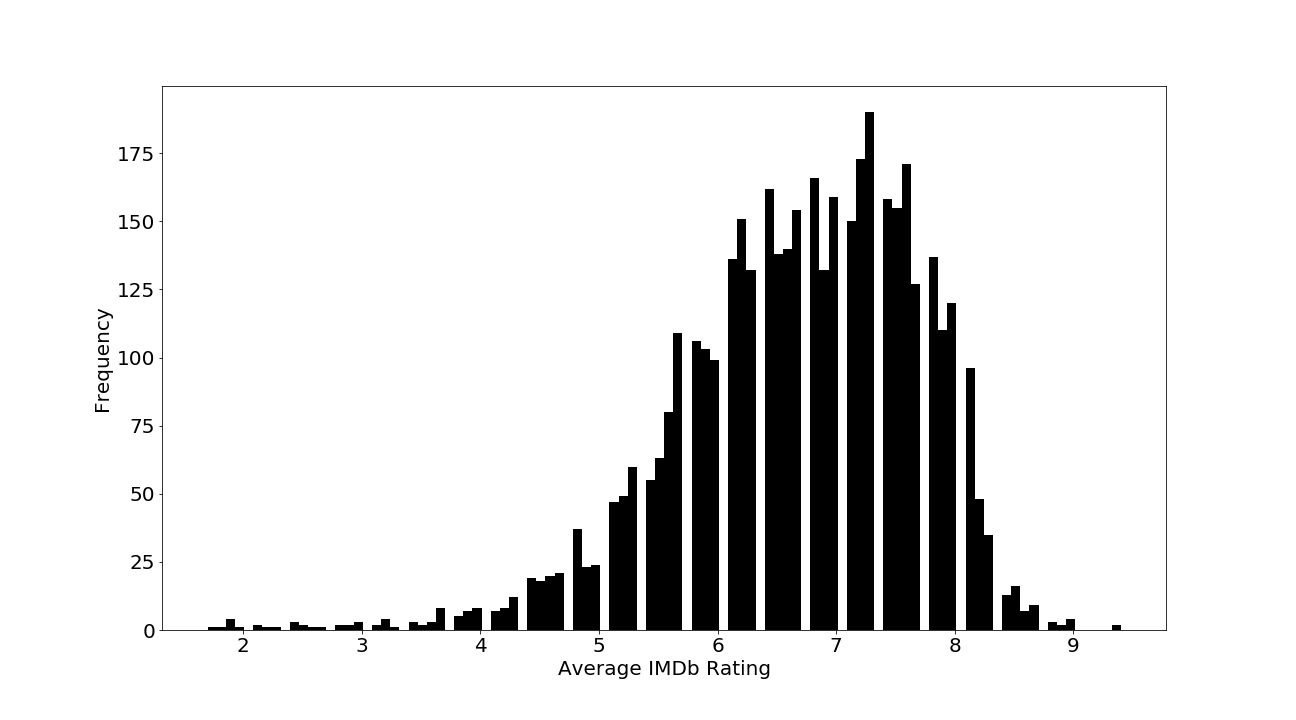
| Mean | Std Dev | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|
| 6.682667 | 1.027169 | 1.7 | 6.1 | 6.8 | 7.4 | 9.4 |
This graph resembles a normal distribution left-skewed and shows
that a good movie would be a movie that has a rating higher
than 6.7.
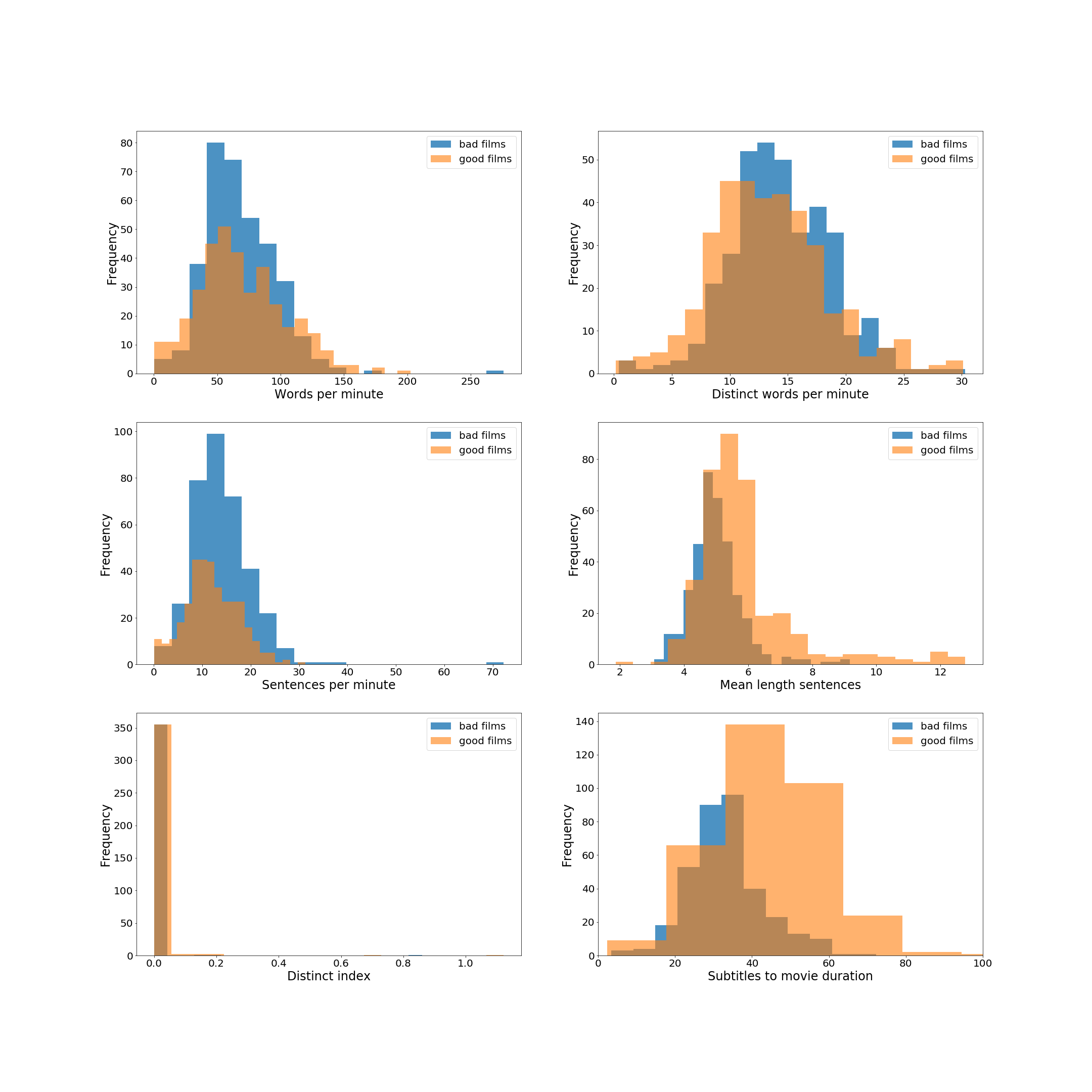
We define two classes with approximately the same number
of movies: good movies and bad movies.
We consider good movies to be movies with average IMDb rating
above 8 and bad movies to be movies with average IMDb
rating below 5.2. We get two classes with 353 and 355
movies respectively.